Have you struggled with adapting your IoT system to new applications and requirements? Is handling configuration updates at both the cloud and edge a challenge? Is synchronizing required data between cloud and edge instances a challenge? This article describes a simple way to model data that eliminates many of these difficulties.
We can scale an IoT system both horizontally (deploy more units) and vertically (add features and address new applications). While the ideas presented in this essay are focused on vertical scale, any simplification will likely help with horizontal scale as well.
Previously, we explored data-centric architectures in IoT systems. This post expands on this by describing how to represent data using Nodes and Points in a way that drastically simplifies IoT data storage, exchange, and synchronization. This is in contrast to encodings and mechanisms used in traditional web and cloud systems.
How are IoT systems different?
IoT systems 🌐 have the following properties, which differentiate them from traditional computer/web/cloud applications:
🌐 IoT systems are inherently distributed (equipment is located in many physically different locations).
🌐 Data must exist concurrently in multiple places (cloud and many edge instances).
🌐 Data is not fully replicated on every instance (a cloud server instance might contain the entire dataset, whereas an edge instance only has a tiny fraction of the dataset that is relevant at that site).
🌐 Instances are not symmetrical (edge instances are very different than cloud instances. It is not a cluster).
🌐 There can be many instances (thousands of edge devices).
🌐 The network is even less reliable (edge systems are often in uncontrolled environments).
🌐 The system must continue to operate during network interruptions (it is not a cluster).
We can attempt to address these challenges by adding constraints such as: 1) data only flows in one direction, 2) device configuration is only changed in the cloud, and 3) the data payload format will not change over time. However, if we think realistically about these constraints, they are impractical for many systems. In distributed computer systems, change is the constant. Because a system can be networked, its capabilities are endless. The ability to connect to new and different systems means new systems and new value can always be created, and things will change. If you don’t, somebody else will.
The “struct”
Cloud/Web APIs have traditionally used various encoding schemes and patterns such as Protobuf, JSON, REST, gRPC, etc. Tools exist to manage schemas, such as GraphQL and JSON Schema. Synchronization mechanisms can be used to manage conflicts (Raft, CRDT, etc.). Most of these schemes assume that the complex struct with multiple and sometimes nested fields is the fundamental element of data representation, storage, and transmission. An example is shown below:
type EmployeeData struct {
ID int
Name string
Age int
Email string
Phone string
Street string
City string
Country string
PostalCode string
EmploymentHistory []struct {
Company string
Position string
Years int
}
Skills map[string]struct {
Proficiency string
YearsExperience int
}
LastUpdated time.Time
}Structs are great — they are a powerful tool for organizing data in a computer program. They are so useful that we have also assumed structs are the best way to store and transfer data outside a program. Thus, we have tables in SQL databases, REST APIs, Protobuf/JSON encoding, etc. This works fairly well and is likely the right solution in many domains. However, we have the following problems with using the struct outside a computer program:
❌ Updating the struct tends to be an all-or-nothing proposition. Fetching the data from a REST API gives you the entire struct. Likewise, when updating, you send the entire struct. There are tools, such as GraphQL, that attempt to solve this problem.
❌ Schema changes are painful. Many very elaborate tools are dedicated to solving the problem of database migrations.
❌ API schema changes are even more painful.
❌ Distributed systems are hard, especially if the struct may be updated by multiple systems concurrently and then requires merging. CRDTs and various other distributed system algorithms attempt to solve this problem, but they are complex.
❌ Nested data is problematic and compounds issues with schema changes and synchronization.
Data in IoT Systems
What are desirable features for handling data in a distributed IoT system?
✔️ We can generate/change data anywhere (in the cloud, at the edge, etc.).
✔️ Synchronization between instances is granular, simple, and reliable.
✔️ Data can flow in any direction.
✔️ One mechanism/transport can be used for all types of data (config, sensor samples, etc.).
✔️ All data changes in the system are recorded in history.
On the surface, this seems like a hard problem. If you have a struct that exists in multiple places, and one field gets changed in one location, and another field gets changed in a second location, how do you reconcile the differences and record what has changed?
As mentioned before, there are solutions such as CRDTs or sending data changes over the wire. Some systems only store changes (mutations) and then compute the current state from all the changes. However, all these schemes are mostly just adding layers of complexity on top of an existing paradigm and are rarely a good fit for IoT systems where you accumulate many thousands of data samples (changes) over time. Maybe it’s time to change the paradigm …
Points and Nodes
What if we rethink our concept of data representation? Instead of trying to make a generic struct the fundamental unit of data, we take a more granular approach and focus on each piece of data in a struct. Can we create a simple unit of data that is easy to store and synchronize, and then build on top of this? This same unit of data is used for everything, including configuration, sample data, notifications, etc. The data unit we have arrived at in the Simple IoT project (after many iterations) is the “Point.”

The data type is typically a string, int, or float, but it can be anything you want.
Points are organized in a hierarchical tree of nodes, where each node contains an array of points.
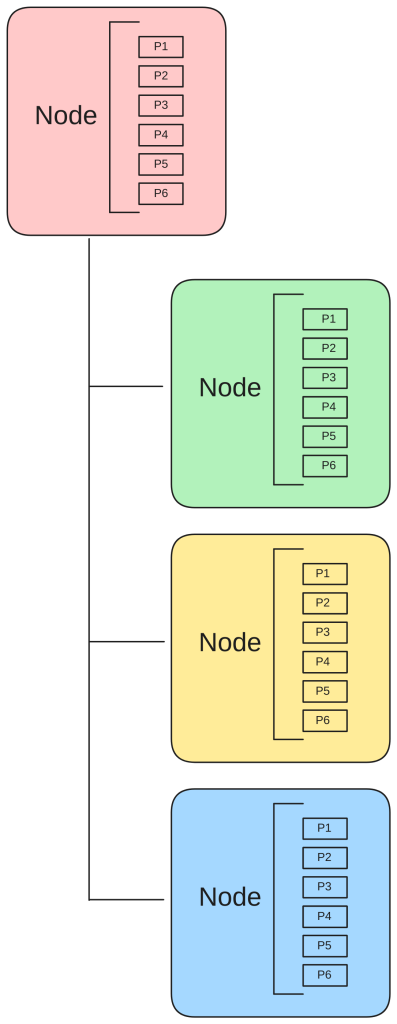
Because a point is defined by both a type and a key, it is possible to construct arrays and maps by populating the key field with either an array index or a map key. This allows us to easily represent one level of structure (arrays and maps) in a node as shown in the following example:
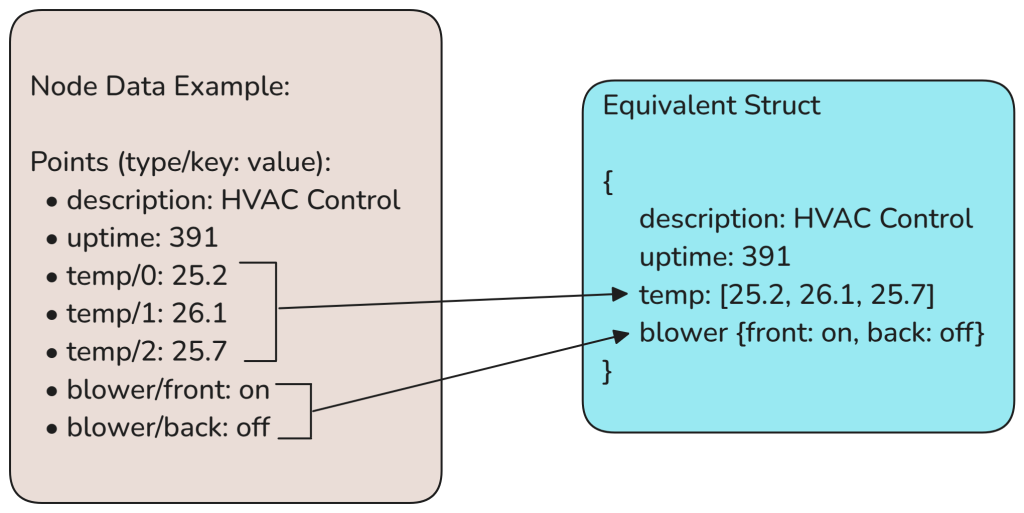
If a deeper structure is required, then nest additional nodes.
Benefits
There are multiple benefits to this data architecture.
✔️ Data is granular. An edge instance can update a node’s sensor reading, and the user can update a node’s config setting in the cloud simultaneously. The points are easily merged as they are received into the node at both locations, without conflicts. This works very well because different users/instances tend to update different points. The exception to this may occur when a user at the edge and a cloud user update a config item at the same time. In this case, we simply use the point with the latest timestamp.
✔️ The storage and communication infrastructure does not change. One of the biggest problems in traditional storage mechanisms and network APIs is that schema and encoding changes can be very painful. If you add a field to a data structure, every piece of code that touches the data as it travels throughout the system needs to be updated. With nodes and points, only the ends of your system need to be updated. Everything in between (transmission, storage, sync, etc) can stay the same.
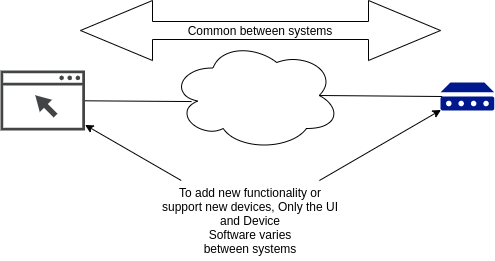
✔️ Introspection and monitoring are easy. Since our data format is simple and fixed, it is easy to watch and decode traffic anywhere to see what is going on.
✔️ Integration is easy. Because we have standardized the data to be very simple, it is easy for one service to provide data that another can use.
✔️ Everything is data that can be acted upon. In the past, we might have had a rules engine that could respond to sensor data changes. Since config changes are now the same kind of data, the rules engine can now respond to and make config changes as well.
✔️ History is easily logged for all changes. Likewise, since config and sensor sample data are now the same type of data, everything that happens in the system can be easily recorded in history. The system is automatically auditable.
✔️ It is efficient. Because the data is granular, only what changes is transmitted and processed.
✔️ It works both internally and externally. While this data scheme was primarily developed to efficiently communicate between systems connected by networks, it also works very well for communicating between threads in an application. When an application is architected this way, it is very easy to extend, it as the communication scheme internally and externally is the same. This architecture scales.
Objections
🚩 Objection #1: But isn’t this a lot of overhead to store a type/key/timestamp/etc with every bit of data?
We need to focus on where the bottlenecks/hard/expensive parts of the system are. Synchronizing data from many different instances over networks is the hard part of IoT systems. Local storage and CPU processing are relatively cheap in comparison. Networks are also relatively slow compared to the additional processing time required to process this data. CPU and storage are now abundant, even on microcontrollers. Development, operations, and deployment are not cheap.
🚩 Objection #2: Nodes and Points are hard to deal with.
True, dealing with raw nodes and points is not as convenient as a struct, but we can create tools that easily convert structs to and from nodes/points. We do it all the time — JSON, Protobuf, etc. Computers are very good at encoding/decoding data — let them do it.
🚩 Objection #3: How do you protect your data if anyone can update anything?
AuthZ/AuthN is a valid concern and has not been fully solved yet. One idea is to authorize access to data at the node level — each user or instance would have access to a set of nodes. However, this says that an edge device could change its own config parameters. Perhaps this is OK because, without physical security, you don’t have true security. It may also be useful to differentiate between read and write access to node data. Ideas are welcome!
🚩 Objection #4: If points for a single struct are flowing in at different times, how do I know when a change is complete and when to process it?
This is also a valid concern. One option is to set a timer that gets reset any time the config changes, and the changes are only processed once the timer expires. With a little creativity, we can probably come up with other schemes to signal the change is complete — perhaps a special point that is sent at the end of a sequence of points.
🚩 Objection #5: What if the data is more complex than what can be represented with a simple data type like a number or string?
You can store anything you want in the point data field (JSON, Protobuf, etc.) This should provide enough flexibility for things like messages, where it probably does not make sense to separate the data into separate points.
🚩 Objection #6: How do you deal with schema changes?
There may be instances where there are point type name changes, node topography changes, etc. In this case, each client, which provides the backend code for a node type, should be responsible for handling any schema changes. This localizes the migration logic to each client (including external clients that plug into the system at runtime) rather than requiring a central system to understand all migrations. A node may contain a version point if necessary.
🚩 Objection #7: Do I have to represent all my data as points?
If data needs to be distributed between instances on a network, then it is very beneficial to use points. However, for local processing of data, there is nothing preventing you from using more conventional techniques, storage, etc.
🚩 Objection #8: How do you store data as nodes and points? SQL databases are not designed for this.
That is an excellent question and part of our research in the Simple IoT project. We are currently using SQLite, but we are moving to NATS Jetstream. Stay tuned!
🚩 Objection #9: Will this scale to a bazillion devices?
Probably not. If you need to connect a bazillion devices, then perhaps AWS IoT or something else is a better fit. However, what we are presenting here is a flexible architecture that will scale over time to many different applications and configurations as your needs evolve and change. How do you want to scale? Think carefully about this, as scaling in one dimension sometimes limits how far you can scale in another.
🚩 Objection #10: This will not work for data sampled at 100 bazillion samples per second.
For moderate data rates, transmitting blocks of data with every point by putting an array of data in a point data field may work. For high-rate data that flows, a custom data encoding and transport will likely be required.
🚩 Objection #11: You can’t depend on time in a computer system, so last-write-wins (LWW) is not reliable.
True, time, like networks, is not always reliable. However, in IoT systems, most of the time, you do not have the same data being edited in multiple locations, so LWW is only used in the rare case where two human users make changes at different locations. A little clock drift is not a huge deal. You can also do things like check if two systems have similar times before you synchronize data between them, and verify a system has a valid time before writing any data. You can also require that every instance in the system has its own RTC clock and that some engineering effort is made to ensure it is reliable and reasonably accurate.
🚩 Objection #12: Why not send commands, events, changes, etc.?
Sending “commands” is a common paradigm in IoT systems, but it is the siren song into complexity. How do you deal with cases where the command does not make it due to a network problem? There are valid cases for events such as orders or notifications, but in most cases, commands/events are an unnecessary abstraction and only complicate things. A sensor is at value X. The config setting is Y. Keep things declarative. Just send the data itself, keep some amount of history, and if you want to know when something changed, look at history. Utilizing new technologies like NATs Jetstream is a critical piece of this puzzle.
🚩 Objection #13: But this is different !?!?
Yup, I’ve never seen anything like it before either. But it works.
Summary
When we want to advance something, we often need to simplify it first. Piling on layers of complexity will only get us so far — at times, we need to go back to ground zero and re-think things.
There are many ways to specify contracts between systems, such as APIs and schemas. A more fundamental contract focuses on a more granular unit of data. Points in an IoT system are like atoms in matter. A Node tree in an IoT system is like the DNA in a living organism. The composition of points and structure of nodes (like atoms and DNA) is infinitely flexible. It is this simplicity and flexibility that allows atoms and DNA to define so many different types of matter and species of organisms. It is time to throw out the custom struct as the defined unit of data between systems and focus on something more granular, flexible, and scalable.
Want to learn more? Check out and follow the Simple IoT project.