With the advent of the browser, cloud, embedded Linux systems, and networked microcontrollers, distributed systems are everywhere. There are many models for communication in distributed systems — we will look at the tradeoffs between three of them. There are many perspectives to consider — initial implementation, client libraries, maintenance, adding features now and in the future, client compute and storage requirements, network bandwidth, data structure, etc. This article will discuss a number of these concerns and present several options.
The motivation for this discussion is synchronizing data in IoT systems where we have the following requirements:
- Data (state or configuration) can be changed anywhere, at edge devices or in the cloud, and this data needs to be synchronized seamlessly between instances. Sensors, users, rules, etc. can all change data. Some edge systems have a local display where users can modify the configuration locally as well as in the cloud. Rules can also run in the cloud or on edge devices and modify state.
- Data bandwidth and allowance is limited in some IoT systems (example Cat-M modems (< 100kb/s) and cellular IoT plans (< 50MB/month)). Additionally, connectivity is not always reliable, and systems need to continue operating if not connected.
The first is the Layered model. In this model, various instances talk directly to other instances. If any information needs to be shared, it is sent directly through an API (application programming interface) call using REST, CoAP, and other protocols — sometimes traveling through multiple layers.

The layered, or API model’s advantage is simplicity — almost anything can connect to a REST endpoint. Most networked devices have built-in support for HTTP. Many companies provide services through REST APIs. Polling is typically used in the layered model to determine when things change, which limits the response time to the polling frequency. There are mechanisms that can be used in a layered architecture to obtain real-time response such as HTTP long polling, WebSockets, Server SIde Events (SSE), callbacks/webhooks, CoAP subscribe/notify, etc. However, an event bus is generally a much cleaner implementation if real-time response is needed. Firewall and security concerns can also make callbacks impractical on edge devices. If a device at the end of a layered architecture needs new information, often multiple layers need to be modified to handle this new information, which can make changes expensive.
A second model is the Event or Message Bus model. Implementations include NATS, MQTT, Kafka, and many others. In this model, every instance in the system is connected to a message bus. All data communication is routed through the bus. Clients can post or subscribe to topics of interest so that updates happen in real-time.

Some advantages of the event bus include real-time response and streaming workflows. All communication and information is on the bus, so if an instance needs to send or receive some information, it simply subscribes or publishes it. Event buses often leverage one connection to the message server so that each message does not need to establish a new connection, which can bring some efficiencies and reduce needed resources (such as number of TCP connections). However, the event bus protocol is considerably more complicated than REST, so a message bus library is typically required to implement the client application.
The third model is the Data-Centric model. In this model, each client instance contains a set of data it is interested in. In the below example, the cloud system has an aggregate of all the data in a system, and the browser and edge instances are subscribed to a subset of the data they are interested in or have access to, represented by the different colored blocks.

The data models the entire system, so if an action (setting an output, sending a notification, etc) is required, a bit of data is changed, and then the system takes action based on this data. The needed data is replicated to each instance in the system and is automatically synchronized in any direction when it changes.
To all you Go programmers out there, this may immediately raise a big red flag. What? Communicate by sharing common data?
Don’t communicate by sharing memory; share memory by communicating.
R. Pike
Pike’s comment is typically used in the context of an application where multiple threads (goroutines) share data in memory, and locks are used to keep multiple threads from writing to it at the same time. This model can be hard to reason about due to race conditions. An analogous model in distributed systems may be a common database that all instances use and all config/state is stored in this remote database. Locks may be analogous to database transactions. A common database is a good solution for many cloud based distributed systems where everything is always connected and, and this model allows data to be modified from multiple locations. However, with IoT systems, we have the following constraints that make it impractical to use a single remote database as our primary configuration/state data store for everything in the system:
- We often don’t have the network bandwidth or data allowance (ex: LoRaWAN or Cat-M modems and low cost cellular IoT plans)
- Network connections are unreliable, and edge instances need to continue working (collect data, run rules, etc.), even if the network is down.
- Network latency can be long — especially with low bandwidth connections.
This leads us to a “local first” data model, where all configuration and state needs to be stored local to an edge device. However, this data is often viewed or edited in the cloud, so it also needs to be present there. We could craft new data structures and messages for every new bit of data and send custom messages over a REST API or event bus every time anything on either end changes. However, a simpler approach is to design a generic data model that can hold any kind of data, and then a mechanism to synchronize this generic data model. Then, adding functionality is much simpler as we can write/read data wherever needed, and synchronization between instances happens automatically with no extra effort. However, we have to learn to work within the constraints of the data model. A new feature might involve tweaking the UI and writing some code on the edge instance. Often, nothing in the middle needs to change:
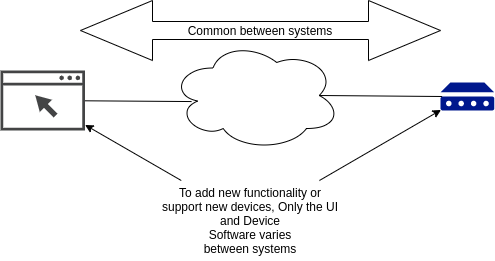
Each instance has its own local copy of whatever data it needs. But instead of the developer needing to manually manage the synchronization of data between systems using custom messages, changes to the data are automatically synchronized in any direction.
The data-centric architecture requires more computing resources and storage to run it — typically an embedded Linux system. The below chart illustrates the trade-offs between client complexity and programming simplicity.

For less capable networked devices such as microcontrollers (ex: Arduino), you may be limited to a layered approach, as HTTP may be the only supported protocol. However, as microcontrollers advance, many of them are now supporting event buses such as MQTT. The cost of a data-centric architecture is an up-front cost when building the base system. As time goes on, the incremental costs of adding features is much lower. Since adding features is typically a continuous, long term exercise, the initial cost is paid back many times over. A data-centric architecture also introduces some discipline in how data is structured, stored, and synchronized. This helps avoid the technical debt that rapidly accrues in less structured approaches.
All architectures have their place. If the application is fixed in functionality, and you only need to send a temperature reading to the cloud once per hour and this is never going to change, then a microcontroller with a layered architecture is fine. If you need to send data in both directions and real-time response is needed, then moving up to an event bus makes sense. If you have devices that have a decent amount of configuration that can be modified at the device and in the cloud, runs rules locally, and features will continually be added to the system, then a data-centric architecture is beneficial. The data-centric architecture requires a more complex system to start with, but the incremental effort to add features down the road is drastically reduced because the developer does not need to worry about the data storage/synchronization problem. Additionally, the data model is available at each instance, so programming is simpler.
It is possible to support multiple architectures in one system. For example, in Simple IoT all data modifications are sent over an event bus which is the primary programming API. A client can connect to the event bus of a local or remote Simple IoT instance. If the local and remote instances are connected using an upstream sync connection, then writes to the common data-set of either instance are automatically synchronized to the other. If a client does not want to implement a local data store, they can connect to a remote instance’s event bus. NATS JetStream is another example of a store built on top of an event bus. Some event bus implementations like NATS allow for easy request/response transactions, which is similar to a layered REST/RPC type interface. Thus clients in a system like Simple IoT can range from simple HTTP clients, to mid-range event-bus clients, to advanced Linux based, data-centric clients with a local data store.
In computer science, focusing on data is typically the right approach.
I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important. Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
Linus Torvalds
Show me your flowcharts and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t usually need your flowcharts; they’ll be obvious.
Fred Brooks
Distributed systems are no different — the focus needs to be on the data. Synchronizing data efficiently and reliably between distributed instances is a hard problem to solve, and the focus of much research and development effort today (example: the Riffle project). This requires some up-front thought, planning, and constraints, but the payoff is simpler data models that result in systems that are more reliable and cost effective over the product life-cycle. Data-centric architectures free developers from the tedium of synchronizing data and allows focus on the application problem at hand. Data-centric architectures also provide discipline and structure around the data synchronization problem that helps avoid technical dept build-up which is a great impediment in the flow of value to end users.
Each distributed system architecture has its place, and with a correct implementation, we can support multiple architectures in one system. This gives us the option to support simple as well as advanced clients, depending on the need. However, as the cost of advanced MPUs systems running Linux such as the Raspberry PI continue to fall, deploying advanced IoT clients to the edge makes a lot of sense.
In future articles, we’ll examine in more depth the techniques used to store and synchronize data in data-centric architectures.
Thanks to Khem Raj, Bruce Stansell, Gina Brake, and Collin Brake for reading drafts of this.