There is a popular quote in medical circles:
When you hear hoofbeats, think of horses, not zebras. — Dr. Theodore Woodward
“Zebra” is the American medical slang for arriving at a surprising, often exotic, medical diagnosis when a more commonplace explanation is more likely.1 What does this have to do with product development? Like the medical profession, we often diagnose problems — we call it debugging. Below are three recent cases where I would have been helped by applying this approach a little more rigorously.
Simple IoT Startup
I recently encountered a bug where the compiled version of Simple IoT would not work on one of my computers. Interestingly, go run worked fine. What was the difference?
At first, it seemed that a race condition was at play – the compiled version was faster, did not have the race detector enabled, and would likely have different characteristics. SIOT is a highly concurrent application with many clients running in parallel. However, after spending some time debugging, I could not find any issues with startup, rather the NATS client in SIOT could not get data from the embedded NATS server. Again, race conditions were assumed, so I tried an external vs. embedded NATS server – no difference.
I finally observed the network traffic with Wireshark and could not observe any NATS traffic in the failing version. The NATS client was not even sending any requests. I then looked at /etc/hosts and there was no localhost entry. After adding this, everything worked properly. See this discussion for more analysis of this issue.
In this case, a race condition was the zebra and the missing entry in /etc/hosts was the horse.
i.MX8 Stability
We recently ran into a problem with a new product that uses a Variscite VAR-SOM-MX8 in a custom baseboard. The software was stable on the Variscite development baseboard, but the same SOM (System on Module) would crash in the custom hardware. The system would never crash until after the Yoe updater initramfs ran and the main rootfs was loaded. Hardware was the immediate suspect — the power supply is probably not able to handle the dynamic load when multiple cores spin up, etc. However, the power looked stable and we could not find any hardware issues. In the end, we found a missing device tree line ("fsl,imx8qm") in the Linux kernel DTS file for the new design. This missing construct caused some critical kernel initialization code not to run.
In this instance, a subtle power problem was the zebra and a missing line in the DTS file was the horse.
STM32H7 USB Instability
In a recent STM32H7 design, we wanted to use a High-speed USB Phy with the STM32H7 and Zephyr. This is not supported by Zephyr yet, but with a few hacks, we got it working. We are trying to push a fair amount of data over this link (10’s Mb/sec) so some optimization and performance work was required on both the sending and receiving end. In the mix of all this, we got a new revision of the target hardware, and at some point started seeing an increase in error rates and the target not enumerating and connecting properly to the host. With a lot of moving parts and a lot of data flowing through the system, it is sometimes hard to pinpoint the problem. In this situation, we tried to narrow the scope by testing older/newer versions of Zephyr and comparing STM32H7 reference designs to the customer hardware. We found the reference designs performed much better. We also learned that a previous version of the custom hardware also performed like the reference designs, so it appeared there was a hardware problem with the latest custom hardware.
When something worked before, and now is experiencing high levels of communication errors, the first thought was signal integrity. On the PCB design, there is a fairly long trace from the USB Phy to the connector, so this was an obvious suspect. Although we were careful to design the PCB such that the impedance of these traces was controlled, there is always the possibility that the PCB vendor did not implement the board stack-up correctly or some other strange issue. One of the engineers analyzed the trace impedance on the old and new boards with a network analyzer. This is a fairly involved test procedure that requires cutting traces, soldering coax cable to the PCB, and a fair amount of expertise. The USB traces between the two revisions looked equivalent and the impedance measured was correct. The next suspect was the high-speed signals between the MCU and Phy — we had changed some of the length matching between the two versions, so perhaps we messed something up. In the process of looking at these signals, the following was observed when scoping the data line:
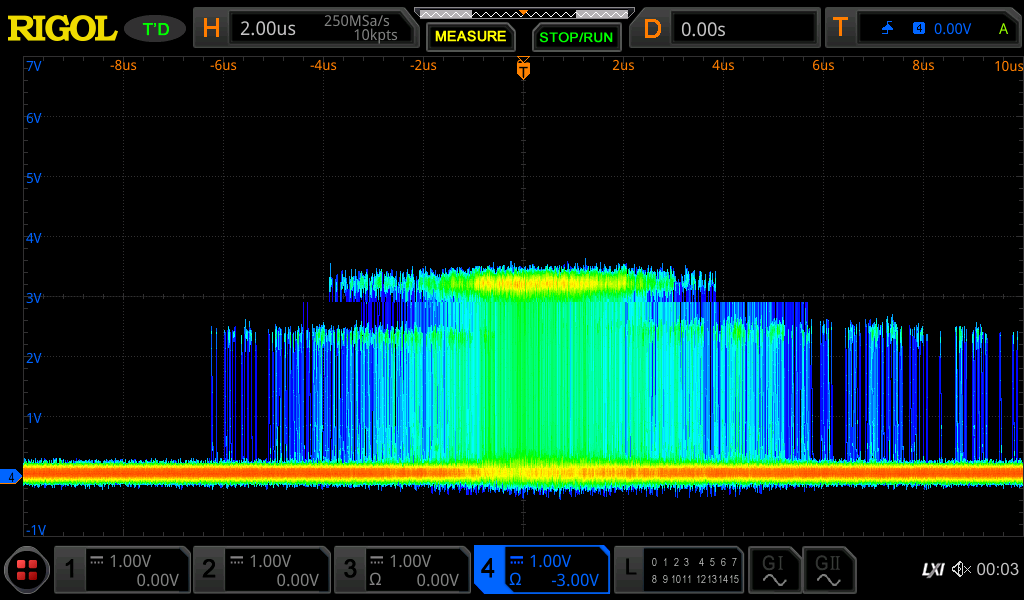
The data line was running at two different voltage levels. The problem ended up being the power to the VDDIO pin on the phy was floating, so the signals from the phy to the MCU were not being driven at the right voltage levels. Simply scoping all the power pins on the Phy would have found this problem in a few minutes.
In this instance, signal integrity was the zebra, and a floating power pin was the horse.
What can we learn?
In all of the above cases, the initial assumptions about the cause of the problem were considerably more complex than the actual problem turned out to be.
| Problem | Zebra (complex) | Horse (simple) |
| SIOT Startup | Race conditions | Host networking config |
| i.MX8 Stability | Dynamic power supply problem | Missing line in device tree file |
| SMT32H7 USB errors | Signal integrity | Floating Phy IO power |
Hindsight is always 20/20, so it’s easy to say we should have solved all these problems more quickly than we did. But there is always something to be learned, and I think as humans, our minds generally go to the more exotic scenario. Part of this may be overconfidence in our ability to get the simple things right, like copying a DTS file from a reference design, or supplying power to a chip. How can we possibly mess up something so simple? So we tend to overlook the simple and obvious and jump to the obscure and exotic, which exercises our most advanced abilities and knowledge. The more experienced we are, the more likely we may be to think this way. To overcome these human tendencies, it is helpful to acknowledge first that they exist (humility), and then put in place a process for future endeavors to help guide us in our debugging efforts. Consider the following maxim:
When debugging a problem, always verify and eliminate the simple/obvious possibilities first. Work from simple to complex.
This is a pragmatic approach because verifying the simple possibilities usually does not take much time, so little is lost in starting there. It may be boring or tedious, which is why we subconsciously tend to avoid these, but we can save a lot of time if we just follow this simple rule. A general process might be:
- isolate the problem as much as possible (remove unused functionality, etc.)
- write down everything you know, possibilities (all of them), and ideas of what you might try.
- sort your ideas from simple to complex and work on the simple ones first.
- document all tests and results.
- meet as a team regularly to discuss results and brainstorm the next steps.
Some specific ideas:
- verify basic network connectivity any time a network is involved, even if on the same machine.
- don’t ignore any problem in the system. Often problems are related, and solving one problem sometimes solves another.
- check that all components involved have good power.
- compare to a known working reference design (both operation and design).
- ask for help in relevant communities.
- review and verify component pin-outs.
- read the datasheets of the components involved.
- read the errata for components.
- work backward from a known working setup.
- with web apps, open the console, and look for errors.
- carefully review boot and build logs and diff with logs from working systems.
- narrow the scope of the problem wherever possible.
- try multiple systems.
- carefully review any changes between working and non-working versions. Verify the operation of any new circuits or code.
- don’t keep doing the same thing and expect different results.
Debugging is an art and a part of the development of any complex system. We must realize that our intuition often fails us in these situations and, with any human weakness, we must have a process to compensate. This debugging process can turn what is often a frustrating and scattered experience into something much more enjoyable and productive. Think horses first, and then zebras!
Pingback: Think Horses, not Zebras (Part 2) – BEC Systems
Comments are closed.