As Embedded Systems become more complex, the complexity of the process to build the software for these systems also increases. As humans, our ability to deal with complexity is limited, so we develop tools and processes to manage the complexity. In the end, these tools and processes are about constraints and patterns. A well-designed tool or process encourages you to do things in a way that is consistent and maintainable, which leads to reliable and predictable results.
As an example, consider using CMake vs standard Makefiles for a C++ application build system. This is a trade-off I often encounter, as my customers are using Linux to build products, and they need to develop a relatively complex software application to implement the product functionality. There are usually a handful of library dependencies as well (such as Qt, OpenCV, etc) — after all, the reason you use Linux is it provides a large amount of advanced functionality that you cannot afford to write yourself.
For a simple application, CMake is somewhat constraining and annoying. Its syntax is a little clumsy, and it is definitely less flexible than a Makefile. Thus some developers conclude that a Makefile is a better choice for Linux application builds. As the application grows, the Makefile also grows, and the number of dependencies increases. Then comes the time to cross compile the application so it will run on the target system. With a little work, we can convince the Makefile to accomplish this. Tool-chain file names and paths are often hard-coded in the Makefile. As the variations of systems the application needs to build on increase, all these variations are coded in the Makefile.
Five years down the road, something major changes. The application developers need some new features in a new version of OpenCV, or the System on Module (SOM) the target system is using just went obsolete. The developer who wrote the original Makefiles is gone. The Linux host distributions have changed. At this point the application build system collapses. So much has changed, and so much is hard coded in the Makefiles that getting them working again is a painful and tedious process. With some effort, they are finally building on one developer’s machine. But on the next developer’s machine, they fail with a different error.
The same dynamic happens when developers hack together tools to build an operating system image for an embedded device. This typically involves things like building the application or Linux kernel manually outside the build system, then writing a script to unpack an image file, insert the new binary, then pack the image file back up. The application build process is heavily dependent on the configuration of the developer’s workstation.
There is a better way. Use tools like Yocto/OpenEmbedded and CMake as they are were meant to be used. These tools do have a learning curve, and require some investment to learn, but in the end they are well worth it. The reason tools like OpenEmbedded and CMake work is that they are consistent, and use the same patterns over and over. We can illustrate the basic architecture of OpenEmbedded in a simple sketch, as shown below. OpenEmbedded is made up of a relatively small number of primitives: layers, recipes, packages, classes, conf files, and tasks.
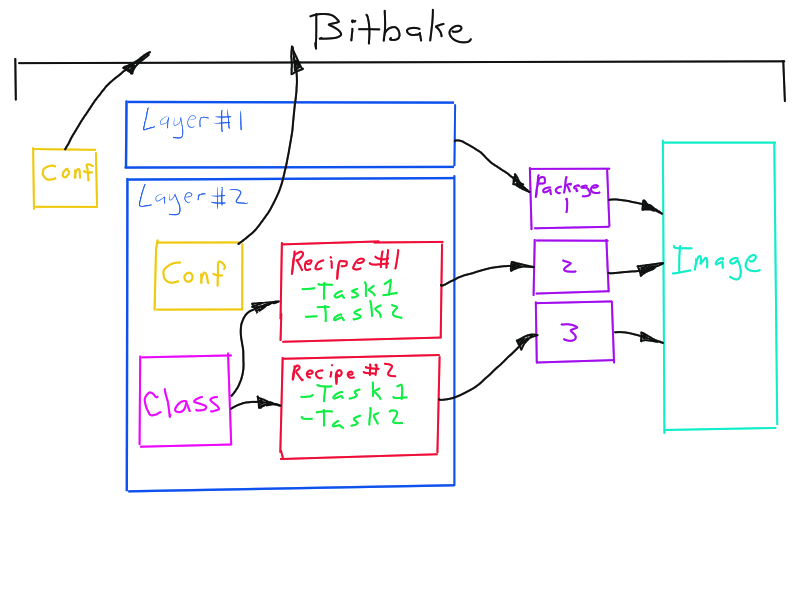
Dependencies can be specified at the layer, recipe, package, and task level. Once these basic concepts are understood, then it is easy to find things in the build system and make necessary modifications. The boundaries are precise and well-defined. These patterns are not as flexible as a Makefile or Bash script, but they abstract huge amounts of complexity. This allows our mind to see the big picture and not get bogged down in thousands of details and to reliably execute extremely complex tasks. The same patterns are used over and over and are easy to recognize. Dependencies are well-controlled. The cost is to understand and use the established patterns and to accept the constraints. These constraints may be a little inconvenient at times. But when you compare this to the work these tools do for you, these inconveniences are relatively minor.
If you are going to build complex products using complex technologies like Linux, then you need powerful tools to manage this complexity. There is a learning curve. You may need to invest in training or hire someone to help you get started. Most other industries recognize this. Car mechanics undergo continuous training to learn how to work on new vehicles/systems. Nurses and other professionals receive training on new techniques and equipment. Build systems also require a significant investment in learning. We routinely hire experts (doctors, dentists, plumbers, carpenters, etc) in our personal lives to do things we don’t know how or have time to do. But somehow many developers think the build system and associated infrastructure should not need attention, can be ignored, or is trivial and can be implemented from scratch. Never mind the fact that the underlying software in the system (bootloader, kernel, and libraries) are many times more complex than the custom application software written for the system. You must be able to maintain it all. You can’t ignore the stuff you did not write — it all has to work. It has to be reliable and predictable. A build system is largely invisible until it starts causing problems.
Getting something working initially is relatively easy; keeping it working for years is another matter. It is similar to product development — building the first prototype that somewhat works often goes fairly quick. Getting something into production is a long, arduous slog. The build system is the foundation of your software project. It must be reliable and predictable because you can’t do much without it. A build system must do its part well without a lot of fuss, so we can focus on the problem being solved. A well implemented build system produces an image ready for installation with a single command and no manual steps. You check source code into git, run the build command, and out pops an image ready to deploy. There is no copying around binaries, etc. The efficiency gained by the effort to implement such a system pays itself back many times over the life of a project — especially those that are produced for 5-10 years.
Yocto and CMake are only used as examples in this article and may not be the best solution for every project. If you have something that is working well, keep doing what you are doing. But if what you are doing is not working, then ask yourself some questions:
- Is my current system the best way to build complex software?
- Is the process to build your project’s software simple and easy to reproduce by any developer on any machine?
- Is it well documented?
- Is it maintainable?
- Is it consistent across all your products?
- Is it reliable and predictable?